PHP is a scripting language, so a PHP parser is needed to run PHP scripts. Furthermore, a webserver like Apache is required to run web applications written in PHP. We assume you already have all that installed (e.g. you installed xampp). Now you have php files in your htdocs-folder and want to open them in the browser, parsed by php and served by your local webserver? But that requires the browser to point to http://localhost/ instead of file://C:/xampp/htdocs/. I solved this by opening a tiny PHP script in the browser that redirects to the correct location. Here is how to set it up:
- Download FileTypesMan (direct download link for x64)
- Unzip FileTypesMan and run FileTypesMan.exe . Confirm the UAC prompt.
- Click Edit / Find and enter “php” in the search field
- If you do not find a row with the extension “.php” in the table, then:
a) Double click a php-file in explorer and assign a default application to launch. This could be a text editor like notepad++, and IDE like Visual Studio Code, or notepad.exe.
b) In FileTypesMan click File / Refresh Desktop now and search again for “php”. You should find it now. - While the row “.php” is selected, click Actions / New action.
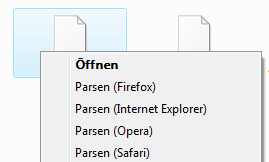
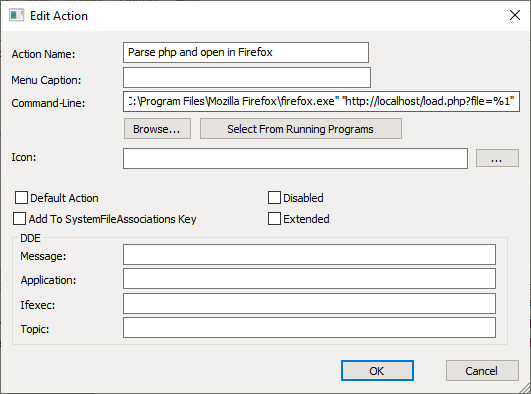
- Assign an action name like
Parse php and open in Firefox - Click “Browse…” and select the executable of the browser that should get launched, e.g.
C:\Program Files\Mozilla Firefox\firefox.exe - Now change the Command-Line so that after the path to the browser, the first argument is
"http://localhost/load.php?file=%1". This makes the browser open said php-file parsed by localhost and pass the filepath as parameterfile. It should look similar as in the screenshot. - Select “Default Action” if you want this action to happen on double-click.
- Click OK. You may create similar actions for other browsers.
- Drop the file
load.phpin your htdocs document root folder with the following content:
<?php
$htdocs = $_SERVER["DOCUMENT_ROOT"];
$webserver = "http://".$_SERVER["HTTP_HOST"];
if(empty($_GET['file'])) $redirectTo = $webserver;
else {
$file = trim(str_replace("%20", " ", str_replace("\\\\", "/", str_replace(DIRECTORY_SEPARATOR, '/', $_GET['file']))));
$inDocumentRoot = strpos($file, $htdocs)!==false;
if(!$inDocumentRoot) {
die('The file is not in the document root!');
}
$redirectTo = $webserver.str_replace($htdocs,"",$file);
}
header('Location: '.$redirectTo);
exit;
Now you can launch php files right from the context menu in Explorer or through double click. You can delete FileTypesMan now.
Please drop a comment it this made your day.